Xkcd en français
 xkcd est une mine d'illustrations pour les enseignants en informatique, et j'ai décidé cette année d'illustrer chaque séance des TP de système/réseau que j'assure en L2 avec un dessin traduit pour l'occasion.
xkcd est une mine d'illustrations pour les enseignants en informatique, et j'ai décidé cette année d'illustrer chaque séance des TP de système/réseau que j'assure en L2 avec un dessin traduit pour l'occasion.
Les difficultés sont multiples : choisir le dessin tout d'abord. Car parmi les quelques centaines de l'auteur, Randall Munroe, il faut en trouver qui ont un rapport plus ou moins direct avec la séance du jour, et je remercie Arnaud de m'avoir fait profiter de sa mémoire et de sa connaissance pointue de xkcd pour m'éviter d'être bloqué sur la fin.
Autre problème, la traduction. Ces courtes vignettes faisant appel à un vocabulaire spécialisé sont assez difficiles à traduire en restant aussi concis. Quand il faut en plus gérer des problèmes de culture geek dont l'équivalent français n'existe pas, ça devient mission impossible. Quant au texte alternatif, c'est souvent difficile même d'y comprendre la blague.
Encore un obstacle, la réalisation. Retrouver une police de caractères qui ressemble à l'écriture - en majuscules - de Randall Munroe n'est pas évident. On trouve quelques essais ici ou là. La police International Playboy, qui contient même la plupart des majuscules accentuées, donne un résultat convenable.
Enfin, dernier problème : la publication et les droits d'auteurs. Eh bien ce n'en est pas un, puisque xkcd est publié sous licence Creative Commons autorisant justement les modifications !
Alors, qu'attendent tous les geeks de France pour lancer une vraie interface collaborative de traduction d'xkcd ?
Il y a eu quelques essais, mais la plupart n'ont pas survécu à quelques dizaines de dessins. Le total, recensé ci-dessous, permet tout de même d'arriver à 11% de la BD. Mais attention, la qualité de traduction n'est pas toujours au rendez-vous :
21 45 77 86 86' 123 129 132 148 156 163 169 171 185 191 195 198 202 208 208' 218 221 224 227 231 232 233 242 244 247 275 275' 287 290 302 302' 303 307 323 327 327' 329 341 342 343 344 345 349 350 353 374 377 378 378' 385 385' 386 397 399 400 405 411 411' 414 425 425' 426 427 428 429 432 433 434 435 436 441 444 445 447 448 451 453 456 456' 469 479 488 488' 530
Si l'on veut lancer une traduction massive, l'idée serait de permettre une collaboration. Difficile si l'on travaille directement sur les images. J'ai donc préparé une interface de traduction d'xkcd en français qui fonctionne seulement en ajoutant le texte sous l'image. Ceux qui le voudront pourront ensuite créer les images, en y insérant ces textes. Pour arriver à une bonne qualité, je propose le système suivant :
- n'importe qui peut envoyer une traduction
- des modérateurs (moi pour l'instant, mais si je peux vous faire confiance, j'accepterai certainement de vous ajouter à la liste) se chargent de la valider pour qu'elle apparaisse sur le site, et de choisir la meilleure (et donc bye bye les robots spammeurs !).

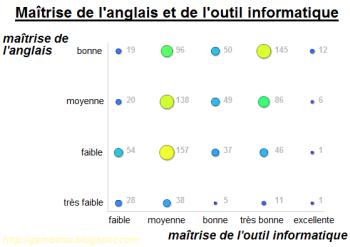
Alors bien sûr, vous allez me dire que la traduction des xkcd est un peu inutile, vu que la connaissance de l'anglais fait partie de la culture geek. Ce n'est pas complètement faux. Un sondage a été organisé cette année pour évaluer la familiarité avec l'outil informatique de tous les entrants en licence de la Faculté des Sciences de l'Université Montpellier 2, dans le cadre d'une UE préparant à l'examen du C2I (Certificat Informatique et Internet). Un millier d'étudiants a répondu, et voici les résultats des deux questions suivantes :
 Si, sur internet, vous arrivez sur une page écrite en anglais :
Si, sur internet, vous arrivez sur une page écrite en anglais :- vous n'y comprenez rien
- vous y déchiffrez quelques mots
- vous pourriez la comprendre en cherchant le sens de quelques expressions
- vous la lisez en comprenant la plupart des phrases
- que vous aurez du mal, qu'il y aura beaucoup (trop ?) de choses à découvrir,
- que ça ira en suivant les TP, et en les travaillant en plus chez vous,
- que suivre les TP vous suffira pour apprendre des choses et les retenir,
- que vous connaissez déjà une bonne partie des choses enseignées en TP, mais que vous en découvrez quelques unes,
- que suivre les TP est pour vous complètement inutile, vous savez déjà tout ou presque.
Comme vous pouvez le constater, la maîtrise de l'anglais augmente en même temps que la maîtrise de l'outil informatique. Alors peut-être que les fous d'ordinateurs continueront à se précipiter sur la version originale de la BD, et que la traduction leur servira seulement en cas de problème. Peut-être qu'ils profiteront de leur maîtrise de la langue pour faire profiter d'xkcd aux allergiques à l'informatique pour lesquels quelques planches sont tout à fait accessibles.
 Voter pour ce billet sur Wikio
Voter pour ce billet sur Wikio








