Jean Véronis nous avait montré comment mieux comprendre les pensées et projets de Nicolas Sarkozy ainsi que "Valéry Giscard d'Estaing et ses amis" en analysant leurs discours et écrits. Et si le traitement automatique des langues vous permettait d'en savoir plus sur vous-même ?
C'est tout à fait possible si vous êtes utilisateur de messagerie instantanée, comme 48% des internautes français et plus de 300 millions de Terriens à ce jour. Enfin, à condition de cocher l'option de votre logiciel permettant l'enregistrement de vos conversations (sous MSN et GAIM en particulier c'est possible), et de bidouiller un peu pour en extraire les informations intéressantes (ou d'attendre la mise en ligne de l'analyseur automatique, quand j'aurai un peu avancé dans la todo list qui a occupé mon été au détriment de ce blog... et de mes vacances).
Rebaptisons vos amis (ou "relations", j'adore l'utilisation de ce terme chez copaindavant) Pote_i, i variant de 1 à... plus ou moins beaucoup, disons n pour rester discrets. Parmi ces n seront présents uniquement ceux que vous contactez régulièrement : en effet, des statistiques significatives ne fonctionnent que sur des données assez conséquentes. Disons plus de 1000 lignes (5000 mots). Appelons Moi_i l'ensemble de vos écrits à Pote_i, et Ami_i, l'ensemble de ses écrits à votre intention. Le premier problème pratique consiste à créer un fichier texte pour chacun de ces ensembles.
Pour Gaim, chaque conversation entre une ouverture et une fermeture de fenêtre est enregistrée dans un fichier à part. Chaque ligne est précédée par l'alias de l'interlocuteur qui parle. J'ai donc programmé un petit utilitaire pour sélectionner uniquement les lignes suivants certains alias sélectionnés. Merci au passage à ceux qui changent d'alias comme de chemise, ou de chanson de Rammstein dans leur playlist (suivez mon regard, ceux qui comprennent la private joke...). Donc bon, voilà, un fichier texte avec tout Ami_i, un autre avec tout Moi_i. Ou plutôt 2n fichiers pour mes n contacts MSN.
Et maintenant, on peut commencer l'analyse. Quels outils pour ça ? En attendant le bidule tout-automatique, décrivons une procédure "alla mano". Allez, commençons par ouvrir Microsoft Word et Excel (ou leurs équivalents libres OpenOffice, on décrit la procédure microsoft-friendly ci-après...). Word, c'est pour leur excellent outil de statistiques. Ironie mise à part, connaître le nombre de mots de votre fichier Ami_i et Moi_i (grâce au menu Outils, Statistiques) est une condition préalable pour toute analyse. En bonus vous avez le nombre de caractères et de lignes qui vous permet après divisions de connaître la longueur moyenne des mots que vous utilisez (4,5 à peu près pour moi, un pote égyptien avec ses "yo" et ses "mec" descend à 3,8), et celle de vos lignes (quelques passages enflammés me font monter à plus de 6 mots par ligne, alors que 4-5 semble plus répandu chez mes interlocuteurs).
Passons maintenant au coeur de l'analyse. Il s'agit d'extraire les mots les plus fréquents. C'est là qu'Excel vous filera un coup de main, en vous permettant de réserver une colonne pour lister les mots de Moi_i ou Ami_i, la suivante pour le nombre d'occurences de chacun, et la dernière pour les fréquences, en divisant la seconde par le nombre de mots du texte total. Ca, c'est pour jouer un peu : intuitez des mots que vous pensez utiliser fréquemment avec Pote_i, ou qu'il utilise fréquemment d'après vous, et mettez-les dans ce tableau. Pour en connaître le nombre d'occurences, en attendant mieux (paragraphe suivant), vous pouvez l'approximer en faisant un Ctrl H (rechercher-remplacer sous Word) et rechercher le mot voulu, le remplacer par lui-même. Cliquer sur Remplacer tout vous donne le nombre d'occurences trouvées. Une fois que vous aurez joué à ça, vous pourrez connaître les mots véritablement les plus fréquents, c'est le (déjà fameux) paragraphe suivant !
Nous cherchons à extraire de Moi_i et Ami_i les mots les plus fréquents avec leur nombre d'occurences. Pour cela, nous allons utiliser un programme de devinez-qui ? Jean Véronis ! Son pratique et rapide Dico. Installez le programme, exécutez-le, ouvrez le fichier texte contenant Moi_i et Ami_i, cochez éventuellement la case Antidico qui permet de cacher les mots les plus fréquents en français dans l'analyse, puis cliquez sur Filtrer. Et là, magique, en quelques secondes, la liste des mots avec leur nombre d'occurences, triable par ordre alphabétique ou par nombre d'occurences, s'affiche.
Et là vous pouvez commencer par finir le jeu qui consistait à deviner quels mots vous utilisiez le plus souvent dans vos conversations avec Pote_i. Vous serez impressionné d'avoir eu de très bonnes intuitions pour certains !
Mais allons plus loin, comment mieux se connaître avec cet outil ? Pour tous les fichiers Moi_i, calculez (en utilisant Excel sur les données de Dico) les fréquences des 50 mots les plus présents. Le faire pour chaque fichier vous permet de voir la variabilité des fréquences, afin de vérifier si la fréquence d'un mot est une constante dans votre conversation, ou si elle est spécifique aux conversations avec un de vos contacts MSN. Puis il s'agit de vérifier si cette haute fréquence est vraiment une de vos spécificités, ou si elle est présente chez tout le monde. En attendant mieux (héhé, un petit nébuloscope des mots les plus fréquents chez vous, contrasté avec le nébuloscope de ces mêmes mots cités par vos contacts), vous pouvez calculer la moyenne des fréquences de ces mots dans tous les fichiers Pote_i, et par exemple représenter le résultat pour les plus fréquents sur un histogramme dans Excel. Si vous voyez un mot au même niveau pour toutes vos barres de Moi_i, et à un niveau très différent pour la barre de moyenne dans Amis_i, vous avez identifié un peu de votre patois bien à vous ! Pour moi, j'aime bien "truc", "genre", "oué"...
Passons maintenant à l'identification de vos relations avec vos amis. Il s'agit là d'identifier les mots qui apparaissent souvent dans Ami_k + Moi_k, et peu souvent dans les Ami_i + Moi_i, pour i différent de k. Pas mal de "cours" avec une camarade de classe par exemple.
Bon, et évidemment on peut passer à une dernière application plus sournoise, celle d'en savoir plus sur vos amis. Vous serez par exemple surpris de remarquer les mots utilisés pour vous interpeler, vous saluer. Pour ça, bien sûr, comparer Ami_k, avec les Ami_i, pour i différent de k. Quelques autres mots intéressants, voire surprenants,dont vous pourrez aussi vérifier la fréquence : "merci", "tu", "je", "!".

La prochaine étape, c'est de mettre tout ça dans un logiciel en précisant que la divulgation d'extraits de correspondance personnelle sans l'avis de ses interlocuteurs est passible de x horreurs. Etape suivante, ajouter une couche d'apprentissage automatique afin de caractériser une relation entre individus à partir de leurs conversations MSN...



 Voter pour ce billet sur Wikio
Voter pour ce billet sur Wikio

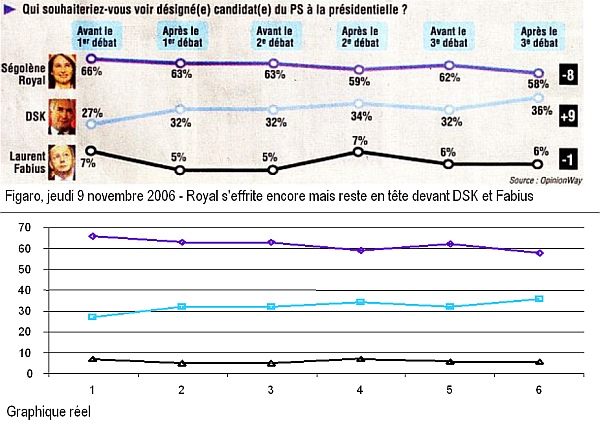



 Il faut donc renforcer un peu le poids des termes peu présents. J'ai donc essayé de considérer non pas les intervalles, mais les intervalles "passés à la racine", ce qui donne l'image de droite. Mieux, mais encore pas ça.
Il faut donc renforcer un peu le poids des termes peu présents. J'ai donc essayé de considérer non pas les intervalles, mais les intervalles "passés à la racine", ce qui donne l'image de droite. Mieux, mais encore pas ça. Ca reste toutefois peu robuste, et je réfléchis donc à une solution alternative, qui découperait l'intervalle des nombres d'occurences de façon "intelligente" par un algorithme de clustering des nombres d'occurences en 10 classes.
Ca reste toutefois peu robuste, et je réfléchis donc à une solution alternative, qui découperait l'intervalle des nombres d'occurences de façon "intelligente" par un algorithme de clustering des nombres d'occurences en 10 classes.





 Alors ?
Alors ?

 Ou pas... Vous voyez ce que ça peut être ?
Ou pas... Vous voyez ce que ça peut être ?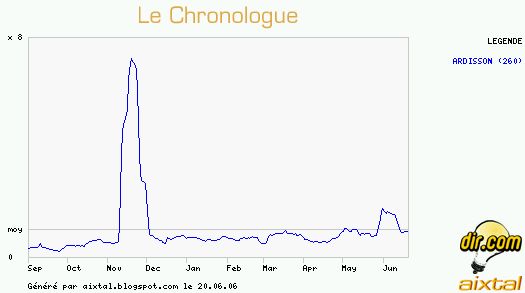



 Affreux parce que pas compréhensible par un oeil non exercé (en fait, le truc permet de visualiser plus d'informations qu'un arbre phylogénétique, mais bon, ne nous étendons pas là-dessus, et tentons plutôt d'obtenir un arbre classique...). Dans le menu Trees, choisissez donc BioNJ si vous êtes chauvin, NJ si vous voulez rédiger
Affreux parce que pas compréhensible par un oeil non exercé (en fait, le truc permet de visualiser plus d'informations qu'un arbre phylogénétique, mais bon, ne nous étendons pas là-dessus, et tentons plutôt d'obtenir un arbre classique...). Dans le menu Trees, choisissez donc BioNJ si vous êtes chauvin, NJ si vous voulez rédiger 












{kind=link}